During the Data Science Immersive (DSI) program in General Assembly (Washington, DC), we usually have a GitHub Enterprise repo for each lecture, which we are asked to fork and clone to our own computers. Periodically, the instructors would post updates after we clone a repo, such as solution code for labs, or updated code-alongs after lectures. Checking for these updates can be tedious, especially when we don’t know exactly when a certain repo would be updated (and it doesn’t help my OCD). So I wrote a script to automate that. I’ve tested and debugged the script pretty extensively during the DSI program. Unfortunately, by the time I have worked out all the kinks, the repos aren’t updated that much anymore. But I hope this will help future cohorts. (Script is shown at the end.)
Flow Chart
To better explain the logic flow of my script, I have made a flow chart:
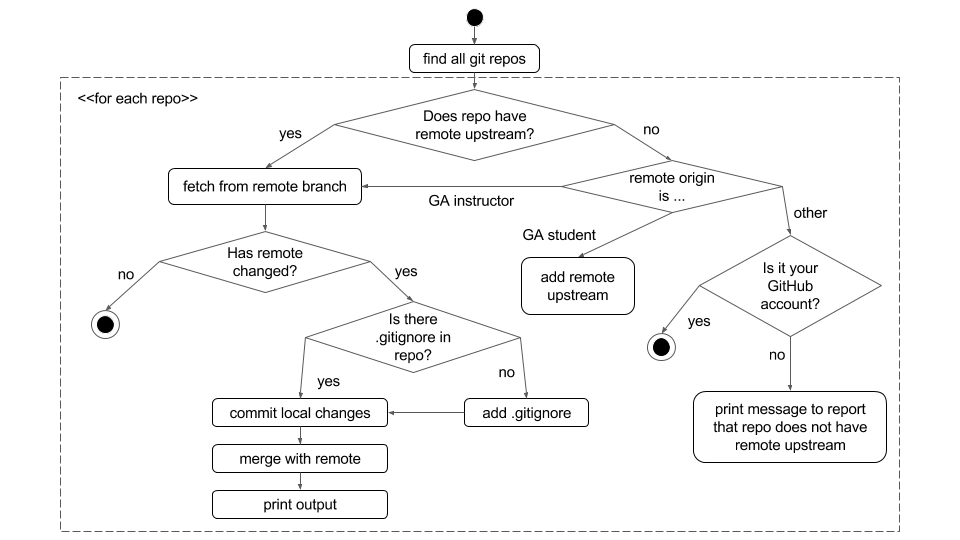
Usage Notes
- You MUST fill in a few variables in the script (lines 6-23). I have given instructions and examples in the comments. When you fill in the GitHub repo patterns (lines 15, 19, and 23), use the SSH (beginning with
git@...), not HTTPS (beginning withhttps://...). This way, you won’t be prompted for username and password every time (which my script isn’t able to handle). - To run the script, you can either use an IDE (e.g. Spyder, PyCharm), or run
python <path to script>in a terminal. - I’ve only tested the script with Python 3, and some of the functions I use from the
subprocesslibrary may be new in Python 3, so I cannot guarantee it’s Python 2 compatible. If you’re using Python 2 (but why?), try it out. If you run into errors, create a virtual environment that runs Python 3 following these instructions. - You may notice that in the script, I first define a
mainfunction (lines 26-55) and then use a conditional to call it at the end (lines 120-121). This is a common format of a Python script. It ensures themainfunction will only be called when the script is directly run (vs. importing the functions in it byimport auto_git_pull). Read more here.
Troubleshooting
You may receive certain error messages. Here are some ways to troubleshoot:
- “Error occurred during merge.”
- This usually means there were conflicts when git was trying to merge your local branch with the remote branch.
In a terminal,
cdinto the directory where the error occurred. Then entergit status; it would tell you what the conflicts are, and give you instructions. Follow these instructions; you’d need to manually solve the conflicts and continue with the merge. Anytime you’re not sure how to proceed, rungit statusagain and see what it says.
- This usually means there were conflicts when git was trying to merge your local branch with the remote branch.
In a terminal,
- “… does not have remote upstream.”
- This means the repo is a public GitHub repo (non-Enterprise) and it doesn’t have a remote upstream. If you forked this repo from someone else, go back to the original repo from which you forked, and copy the “Clone or download” path (again, choose SSH, not HTTPS). Then, in a terminal,
cdinto the repo, and entergit remote add upstream <copied path>.
- This means the repo is a public GitHub repo (non-Enterprise) and it doesn’t have a remote upstream. If you forked this repo from someone else, go back to the original repo from which you forked, and copy the “Clone or download” path (again, choose SSH, not HTTPS). Then, in a terminal,
If you run into errors not described above, feel free to shoot me a message.
I’ll describe how to set up a cronjob to run the script periodically in another blog post. Stay tuned!