When you run code that may take a while, for example, webscraping, or extracting text from many xml files, you may want to write the output to the disk as you go for various reasons. One is to release memory, since you are not storing everything in memory; the other one is to prevent losing all the work in case there is a power outage, internet outage, or an error is thrown on your code.
The code is very simple, but it’s the mentality of saving work as you go that counts.
Opening a file in “append” mode (open(file, 'a') will create a new file if the file doesn’t already exist. For example:
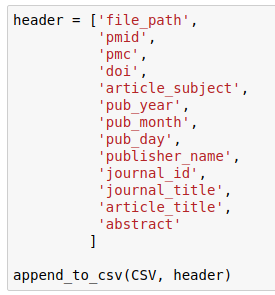
This creates a csv file with only the header. (Note: I already define CSV earlier in the process.)
Bonus 1
Here is a trick to combine two csv files. In a terminal, run the command line:
tail -n +2 <path to csv_1> >> <path to csv_2>
Be sure to replace <path to csv_1> and <path to csv_2> with actual paths. This will append csv_1 to the end of csv_2.
+2 means the second line till the end of csv_1 (because the header (the first line) in csv_1 does not need to be appended to csv_2).
Bonus 2
One more trick: you can run bash command lines in a Jupyter notebook by starting the line with !.
For example, !mkdir dataset will create a subdirectory called dataset in the same directory containing your Jupyter notebook.