In my last blog post, I have discussed the importance of exploratory data analysis (EDA) and the use of the describe method in pandas. Today I’ll discuss another aspect of EDA: checking for missing and duplicated data.
Check for missing data
Missing data directly affects what you need to do in the downstream step — data cleaning, therefore checking for missing data should be a routine during EDA. I’ve written the following function, which prints out the number and percentage of null values in each column of a pandas DataFrame:
This is what the output looks like on a dataframe I’m currently working on:
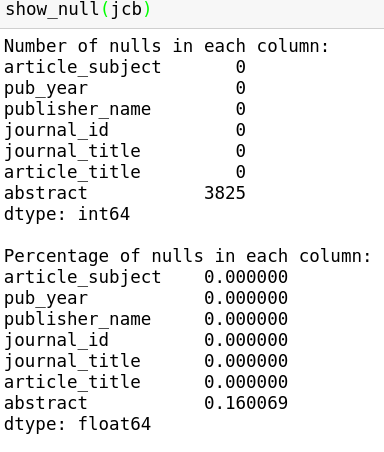
Once the scope of missing data is inspected, you need to make decisions on how to handle it. Should you drop the observation (row)? Should you drop the variable (column)? Or should you use more sophisticated methods (e.g. Multiple Imputation by Chained Equations) to fill in the missing data? Handling missing data is beyond the scope of this blog, but knowing what you’re missing is the first step.
Check for duplicate data
Duplicate data is kind of like the flip side of missing data. Having too much of the same data would not help your model. It is also more computationally costly to process, and may give the duplicate data more weight in your models than it should have. So it’s a good practice to check for duplicate data as a routine.
The following function computes the number of duplicate rows in a pandas DataFrame, and you can also choose to show the duplicate rows either sorted (more computationally expensive) or unsorted.
Two more things about the duplicated method in pandas:
-
It does not consider the index, i.e., if two rows have exactly the same values across columns but have different indices, they will be marked as duplicate rows. So depending on how meaningful the indices are, the rows may or may not be true duplicates.
-
It has a
subsetargument, which allows you to specify column(s) to consider when identifying duplicates.
That’s it for today! Again, hope you find the code here useful.